about
Blog: Object Oriented Design
11/23/2024
Blog: Object Oriented Design
Inheritance, composition, aggregation, using
About
click to toggle Site Explorer
Initial Thoughts:
Goals:
The goals of object oriented design are to support program abstractions by encapsulating implementation details in class instances, provide composability through class relationships, and support extensibility through inheritance and paramaterization using C++ templates or generics with C# and Java.Encapsulation:
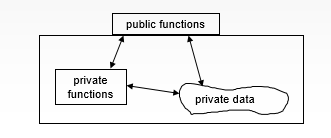
Figure 1 - Encapsulation
- Private methods and member data are accessible to every member of the class but inaccessible to clients and derived classes.
- Protected methods and member data are also accessible to derived classes, but not to clients.
- Public methods provide an interface for clients and derived classes. We don't make member data public.
Class Relationships:
Classes support inheritance, composition, aggregation, and using relationships.
Inheritance:
When a derived class D inherits from a base B it
inherits all of the member functions and member data of the base class except, when using C++, for constructors, assignment operators, and destructors.
The derived class may add additional methods and member data.
Composition:
composition is a strong ownership relation. A composed part P becomes an integral part of the composer C. P is constructed at the same time as C and shares
its lifetime. C++ supports composition with every user-defined type as well as types defined by the language. Java and C# have two kinds of types, value types
and reference types. Composition of value types is supported by those languages, but composition of reference types is not supported.
Aggregation:
Aggregation is a weak ownership relation. An aggregated part P may be instantiated by its aggregator A, but instantiation is not guaranteed to occur as that requires
code in the aggregator to explicitly create an instance on the heap. The aggregating class A composes a handle to the part P, but the instance of P itself
resides on the heap from the time of its instantiation. And so, the lifetime of P is less than the lifetime of the A. C++ supports aggregation of
user-defined types and types defined by the language, placing instances on the native heap. Java and C# support aggregation for reference types and for
value types if they are boxed, which wraps them with an instance of a reference type on the managed heap.
Using:
Using relationships provide access via references to instances of types R that are not owned by the using class U. C++, Java, and C# support using relationships
in the same way. References to R are passed to an instance of U via a method argument.
Substitution:
All Object Oriented Programming (OOP) languages support substitution:
Liskov Substitution Principle:
"Functions that use pointers or references statically typed to some base class must be able to use objects of classes derived from the base through
those pointers or references without any knowledge specialized to the derived classes."6
Sharing:
Interface Segregation:
Interface Segregation Principle
"Clients should not be forced to depend upon interfaces they do not [fully] use." "If we have to change an interface we affect even those clients
that do not use the features we change"6.
Dependency Inversion:
Dependency Inversion Principle:
"High level components should not depend upon low level components. Instead, both should depend on abstractions." "Abstractions should not depend on details.
Details should depend upon the abstractions."6
Patterns:
- Structured programming uses global functions assembled into packages to represent a program's structure and behavior. The C programming language provides facilities for structured programming exclusively.
- Functional programming attempts to bring the rigor of mathematics to program development. Initially based on the lambda calculus, functional languages like Haskell and Erlang use pure functions that have no side effects and accept and return other functions as part of their operation. State in functional programs is immutable with loops implemented through recursion.
- Generic programming defines classes and functions using type parameters that can be instantiated with concrete types at the time an application is built. Java generics and C++ templates support this programming style.
- Object Oriented Design is based on the use of classes and class relationships to structure programs. In C++ a class may use, compose, or aggregate any other type and inherit from any non-primitive type, whether provided by the language or defined by a user. In Managed languages like C# and Java types are segregated into value types which are copy-able and reference types that are not. Value types and handles to reference types live in their program's set of stack frames while all instances of reference types live in the program's managed heap. Reference types cannot compose other reference types. They aggregate them, e.g., they compose a handle to the reference type which points to the handle's instance in the managed heap. They may inherit any single type that is not sealed and not primitive. Java and C# do support multiple inheritance of interfaces.
- We categorize packages as "application side" or "solution side" depending on whether they focus on meeting the requirements of their program or some lower-level supporting role. Solution side classes are very often constructed to be reusable in other programs by giving them flexiblity through template parameterization or inheritance hooks. Application side classes are far less often reusable as they focus on the obligations of one specific program.
- Robert Martin wrote a series of white papers, now hosted on his blog, which present the principles discussed here and others as well. Here's a link to one of his variations on these principles and related topics: Principles.
